I am writing this post as a future reminder for myself.
I decided to install a Linux OS on an old laptop. And I didn’t want a Debian system (I am using Ubuntu at the office). So I went to Fedora. I just want to get my hands more dirty on Linux.
Recently I found myself in several situations where I just couldn’t write code. Or at least, “good code”
First, I had “writer’s block”. I just could not see what was going to be my next test to write.
I could not find the name for the class / interface I needed.
Second, I just couldn’t simplify my code. Each time I tried to change something (class / method) to a simpler construction, things got worse. Sometimes to break.
I was stuck.
The Tasks
Refactor to Patterns
One of the situation we had was to refactor a certain piece in the code.
This piece of code is the manual wiring part. We use DI pattern in ALL of our system, but due to some technical constraints, we must do the injection by hand. We can live with that.
So the refactor in the wiring part would have given us a nice option to change some of the implementation during boot.
Some of the concrete classes should be different than others based on some flags. The design patterns we understood we would need were: Factory Method and Abstract Factory
The last remark is important to understand why I had those difficulties.
I will get to it later.
New Module
Another task was to create a new module that gets some input items, extract data from them, send it to a service, parse the response, modify the data accordingly and returns items with modified data.
While talking about it with a peer, we understood we needed several classes.
As always we wanted to have high quality code by using the known OOD principles wherever we could apply them.
So What Went Wrong?
In the case of refactoring the wiring part, I constantly tried to immediately create the end result of the abstract factory and the factory method that would call it.
There are a-lot of details in that wiring code. Some are common and some needed to be separated by the factory.
I just couldn’t find the correct places to extract to methods and then to other class.
Each time I had to move code from one location and dependency to another.
I couldn’t tell what exactly the factory’s signature and methods would be.
In the case of the new module, I knew that I want several classes. Each has one responsibility. I knew I want some level of abstraction and good encapsulation.
So I kept trying to create this great encapsulated abstract data structure. And the code kept being extremely complicated.
Important note: I always to test first approach.
Each time I tried to create a test for a certain behavior, it was really really complicated.
I stopped
Went to have a cup of coffey.
I went to read some unrelated stuff.
And I talked to one of my peers.
We both understood what we needed to do.
I went home…
And then it hit me
The problem I had was that I knew were I needed to go, but instead of taking small steps, I kept trying to take one big leap at once.
Which brings me to the analogy of Agile to good programming habits (and TDD would be one of them).
Agile and Programming Analogy
One of the advantages in Agile development that I really like is the small steps (iteration) we do in order to reach our goal.
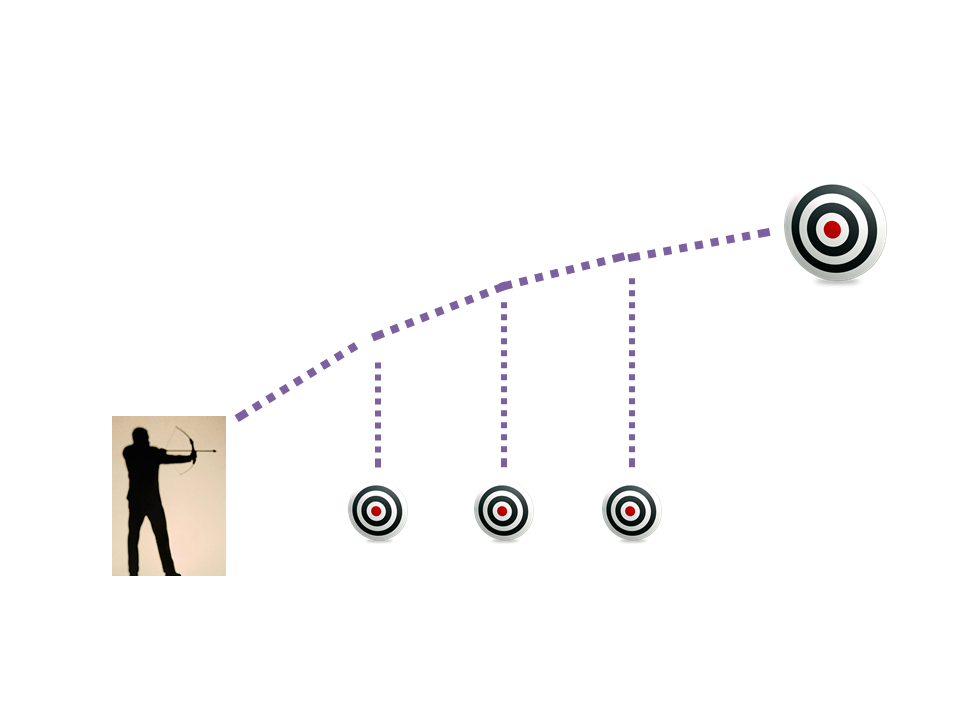
Check the two pictures below.
One shows how we aim towards a far away goal and probably miss.
The other shows how we divide to iterations and aim incrementally.
Aiming From Far
Aiming Iterative and Incremental
Develop in Small Incremental Iterations
This is the moral of the story.
Even if you know exactly how the structure of the classes should look like.
Even if you know exactly which design pattern to use.
Even if you know what to do.
Even if you know exactly how the end result should look like.
Keep on using the methods and practices that brings you to the goal in the safest and fastest way.
Do small steps.
Test each step.
Increment the functionality of the code in small chucks.
TDD.
Pair. Keep calm.
General
In this post I want to go over Law of Demeter (LoD).
I find this topic an extremely important for having the code clean, well-designed and maintainable.
In my experience, seeing it broken is a huge smell for bad design.
Following the law, or refactoring based on it, leads to much improved, readable and more maintainable code.
So what is Law of Demeter?
I will start by mentioning the 4 basic rules:
Law of Demeter says that a method M of object O can access / invoke methods of:
O itself
M’s input arguments
Any object created in M
O’s parameters / dependencies
These are fairly simple rules.
Let’s put this in other words: Each unit (method) should have limited knowledge about other units.
Metaphors
The most common one is: Don’t talk to strangers
How about this:
Suppose I buy something at 7-11.
When I need to pay, will I give my wallet to the clerk so she will open it and get the money out?
Or will I give her the money directly?
How about this metaphor:
When you take your dog out for a walk, do you tell it to walk or its legs?
Why do we want to follow this rule?
We can change a class without having a ripple effect of changing many others.
We can change called methods without changing anything else.
Using LoD makes our tests much easier to construct. We don’t need to write so many ‘when‘ for mocks that return and return and return.
It improves the encapsulation and abstraction (I’ll show in the example below).
But basically, we hide “how things work”.
It makes our code less coupled. A caller method is coupled only in one object, and not all of the inner dependencies.
It will usually model better the real world.
Take as an example the wallet and payment.
Counting Dots?
Although usually many dots imply LoD violation, sometimes it doesn’t make sense to “merge the dots”.
Does: getEmployee().getChildren().getBirthdays()
suggest that we do something like: getEmployeeChildrenBirthdays() ?
I am not entirely sure.
Too Many Wrapper Classes
This is another outcome of trying to avoid LoD.
In this particular situation, I strongly believe that it’s another design smell which should be taken care of.
As always, we must have common sense while coding, cleaning and / or refactoring.
Example
Suppose we have a class: Item
The item can hold multiple attributes.
Each attribute has a name and values (it’s a multiple value attribute)
The simplest implementations would be using Map.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Let’s have a class ItemsSaver that uses the Item and attributes:
(please ignore the unstructured methods. This is an example for LoD, not SRP 🙂 )
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
Suppose I know that it’s a single value (from the context of the application).
And I want to take it. Then the code would look like:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
I think that it is clear to see that we’re having a problem.
Wherever we use the attributes of the Item, we know how it works. We know the inner implementation of it.
It also makes our test much harder to maintain.
Let’s see an example of a test using mock (Mockito):
You can see imagine how much effort it should take to change and maintain it.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
We can use real Item instead of mocking, but we’ll still need to create lots of pre-test data.
Let’s recap:
We exposed the inner implementation of how Item holds Attributes
In order to use attributes, we needed to ask the item and then to ask for inner objects (the values).
If we ever want to change the attributes implementation, we will need to make changes in the classes that use Item and the attributes. Probably a-lot classes.
Constructing the test is tedious, cumbersome, error-prone and lots of maintenance.
Improvement
The first improvement would be to ask let Item delegate the attributes.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
We are (almost) hiding totally the implementation of attributes from other classes.
The client classes are not aware of the implementation expect two cases:
Item still knows how attributes are built.
The class that creates Item (whichever it is), also knows the implementation of attributes.
The two points above mean that if we change the implementation of Attributes (something else than a map), at least two other classes will need to be change. This is a great example for High Coupling.
The Next Step Improvement
The solution above will sometimes (usually?) be enough.
As pragmatic programmers, we need to know when to stop.
However, let’s see how we can even improve the first solution.
Create a class Attributes:
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters.
Learn more about bidirectional Unicode characters
(Did you noticed? The implementation of attributes inside item was changed, but the test did not need to. This is thanks to the small change of delegation.)
In the second solution we improved the encapsulation of Attributes.
Now even Item does not know how it works.
We can change the implementation of Attributes without touching any other class.
We can make different implementations of Attributes:
– An implementation that holds a Set of values (as in the example).
– An implementation that holds a List of values.
– A totally different data structure that we can think of.
As long as all of our tests pass, we can be sure that everything is OK.
What did we get?
The code is much more maintainable.
Tests are simpler and more maintainable.
It is much more flexible. We can change implementation of Attributes (map, set, list, whatever we choose).
Changes in Attribute does not affect any other part of the code. Not even those who directly uses it.
Modularization and code reuse. We can use Attributes class in other places in the code.
About JVDrums
It was written around 6 years ago (This is the date as shown in the commit history: 2008-05-09).
The project is a MIDI client for Roland Electronic Drums for uploading and backing up drumsets.
It was an early attempt to use testing during development (an early TDD attempt).
I used TestNG for the testing.
Initially I created it for my own model, which is Roland TD-12. I needed a small app for uploading drumsets which other users created and sent me.
When I published it in some forums I was asked to develop the client for other models (TD-6, TD-10).
That was cool, as I didn’t have the real module (each model has it’s own module), so how could I develop and test for it?
Each module has MIDI specification, so I downloaded them from Roland’s website.
Then, I created tests that simulated the structure of the MIDI file and I could hack the upload, download and editing.
I also created a basic UI interface using Java-Swing.
I am working on a presentation about the ‘Single Responsibility Principle’, based on my previous post.
It take most of my time.
In the meantime, I want to share a sample code of how I use to test inner fields in my classes.
I am doing it for a special case of testing, which is more of an integration test.
In the standard unit testing of the dependent class, I am using mocks of the dependencies.
The Facts
All of the fields (and dependencies in our classes are private
The class do not have getters for its dependencies
We wire things up using Spring (XML context)
I wan to verify that dependency interface A is wired correctly to dependent class B
One approach would be to wire everything and then run some kind of integration test of the logic.
I don’t want to do this. It will make the test hard to maintain.
The other approach is to check wiring directly.
And for that I am using reflection.
Below is a sample code of the testing method, and the usage.
Notice how I am catching the exception and throws a RuntimeException in case there is a problem.
This way, I have cleaner tested code.
This file contains hidden or bidirectional Unicode text that may be interpreted or compiled differently than what appears below. To review, open the file in an editor that reveals hidden Unicode characters. Learn more about bidirectional Unicode characters
Introduction
In this post I would like to cover the Single Responsibility Principle (SRP).
I think that this is the basis of any clean and well designed system.
…In object-oriented programming, the single responsibility principle states that every class should have a single responsibility, and that responsibility should be entirely encapsulated by the class. All its services should be narrowly aligned with that responsibility….
From Clean Code:
A class or module should have one, and only one, reason to change.
So if a class (or module) needs to be modified for more than one reason, it does more than one thing. I.e. has more than one responsibility.
Why SRP?
Organize the code
Let’s imagine a car mechanic who owns a repair shop.
He has many many tools to work with. The tools are divided into types; Pliers, Screw-Drivers (Phillips / Blade), Hammers, Wrenches (Tubing / Hex) and many more.
How would it be easier to organize the tools?
Few drawers with different types in each one of them?
Or, many small drawers, each containing a specific type?
Now, imagine the drawer as the module. This is why many small modules (classes) are more organized then few large ones.
Less fragile
When a class has more than one reason to be changed, it is more fragile.
A change in one location might lead to some unexpected behavior in totally other places.
Low Coupling
More responsibilities lead to higher coupling.
The couplings are the responsibilities.
Higher coupling leads to more dependencies, which is harder to maintain.
Code Changes
Refactoring is much easier for a single responsibility module.
If you want to get the shotgun effect, let your classes have more responsibilities.
Maintainability
It’s obvious that it is much easier to maintain a small single purpose class, then a big monolithic one.
Testability
A test class for a ‘one purpose class’ will have less test cases (branches).
If a class has one purpose it will usually have less dependencies, thus less mocking and test preparing.
The “self documentation by tests” becomes much clearer.
Easier Debugging
Since I started doing TDD and test-first approach, I hardly debug. Really.
But, there come times when I must debug in order to understand what’s going on.
In a single responsibility class, finding the bug or the cause of the problem, becomes a much easier task.
What needs to have single responsibility?
Each part of the system.
The methods
The classes
The packages
The modules
How to Recognize a Break of the SRP?
Class Has Too Many Dependencies
A constructor with too many input parameters implies many dependencies (hopefully you do inject dependencies).
Another way too see many dependencies is by the test class.
If you need to mock too many objects, it usually means breaking the SRP.
Method Has Too Many Parameters
Same as the class’s smell. Think of the method’s parameters as dependencies.
The Test Class Becomes Too Complicated
If the test has too many variants, it might suggest that the class has too many responsibilities.
It might suggest that some methods do too much.
Class / Method is Long
If a method is long, it might suggest it does too much.
Same goes for a class.
My rule of thumb is that a class should not exceed 200-250 LOC. Imports included 😉
Descriptive Naming
If you need to describe what your class / method / package is using with the AND world, it probably breaks the SRP.
Class With Low Cohesion
Cohesion is an important topic of its own and should have its own post.
But Cohesion and SRP are closely related and it is important to mention it here.
In general, if a class (or module) is not cohesive, it probably breaks the SRP.
A hint for a non-cohesive class:
The class has two fields. One field is used by some methods. The other field is used by the other methods.
Change In One Place Breaks Another
If a change in the code to add a new feature or simply refactor broke a test which seems unrelated, it might suggest a breaking the SRP.
Shotgun Effect
If a small change makes a big ripple in your code. If you need to change many locations it might suggest, among other smells, that the SRP is broken.
Unable to Encapsulate a Module
I will explain using Spring, but the concept is important (not the implementation).
Suppose you use the @Configuration or XML configuration.
If you can’t encapsulate the beans in that configuration, it should give you a hint of too much responsibility.
The Configuration should hide any inner bean and expose minimal interfaces.
If you need to change the Configuration due to more than one reason, then, well, you know…
How to make the design compliant with the Single Responsibility Principle
The suggestions below can apply to other topics of the SOLID principles.
They are also good for any Clean Code suggestion.
But here they are aimed for the Single Responsibility Principle.
Awareness
This is a general suggestion for clean code.
We need to be aware of our code. We need to take care.
As for SRP, we need to try and catch as early as we can a class that is responsible for too much.
We need to always look for a ‘too big method’.
Testable Code
Write your code in a way that everything can be tested.
Then, you will surly want that your tests be simple and descriptive.
TDD
(I am not going to add anything here)
Code Coverage Metrics
Sometimes, when a class does too much, it won’t have 100% coverage at first shot.
Check the code quality metrics.
Refactoring and Design Patterns
For SRP, we’ll mostly do extract-method, extract-class, move-method.
We’ll use composition and strategy instead of conditionals.
Clear Modularization of the System
When using a DI injector (Spring), I think that Configuration class (or XML) can pinpoint the modules design. And modules’ single responsibility.
I prefer to have several small to medium size of configuration files (XML or Java) than having one big file / class.
It helps see the responsibility of the module and easier to maintain.
I think that the configuration approach of injection has an advantage of annotation approach. Simply because the Configuration approach put the modules in the spotlight.
Conclusion
As I mentioned in the beginning of this post, I think that Single-Responsibility-Principle is the basis of a good design.
If you have this principle in your mind while designing and developing, you will have a simpler more readable code.
Better design will be followed.
One Final Note
As always, one needs to be careful on how to apply practices, code and design.
Sometimes we might do over-work and make simple things over complex.
So a common sense must be applied at any refactor and change.